


Ultra-fast 2D & 3D Hilbert space-filling curve encode/decode kernels for Python.

2D Hilbert curves (nbits 1..5) and 3D Hilbert curves (nbits 1..4, animated).
✨ New in v0.3.0: PyTorch API + GPU-accelerated kernels with Triton!
New in v0.4.0: Morton/z-order curves
This library is performance-first and implemented entirely in Python. It provides fast Hilbert encode/decode kernels for both CPU and GPU, with convenient high-level APIs for NumPy and PyTorch, low-level kernel accessors and clean integration with torch.compile for fusion with surrounding code. For completeness, it also includes Morton/z-order curve kernels.
The hot kernels are JIT-compiled with Numba (CPU) and Triton (GPU) and tuned for:
- Branchless, fully unrolled inner loops
- Small, L1-cache-friendly lookup tables (LUTs)
- Reduced dependency chains for better ILP and MLP (e.g. state-independent lookups)
- Multi-threading for batch processing
- SIMD via LLVM vector intrinsics (CPU)
- Reduced register pressure (GPU)
HilbertSFC is orders of magnitude faster than existing Python implementations. It also outperforms the Fast Hilbert Rust crate by a factor of ~8x. In fact, HilbertSFC takes only ~6 CPU cycles per point for 2D encode/decode of 32-bit coordinates.
| Implementation | ns/pt (enc) | ns/pt (dec) | Mpts/s (enc) | Mpts/s (dec) |
|---|---|---|---|---|
| hilbertsfc (multi-threaded) | 0.41 | 0.48 | 2410.39 | 2084.98 |
| hilbertsfc (Python) | 1.38 | 1.59 | 726.68 | 629.52 |
| fast_hilbert (Rust) | 12.24 | 12.03 | 81.67 | 83.11 |
| hilbert_2d (Rust) | 121.23 | 101.34 | 8.25 | 9.87 |
| hilbert-bytes (Python) | 2997.51 | 2642.86 | 0.334 | 0.378 |
| numpy-hilbert-curve (Python) | 7606.88 | 5075.58 | 0.131 | 0.197 |
| hilbertcurve (Python) | 14355.76 | 10411.20 | 0.0697 | 0.0961 |
System info: Intel Core Ultra 7 258v, Ubuntu 24.04.4, Python 3.12.12, Numba 0.63.1
Additional benchmarks and details are available in the benchmark-cpu.md.
For a deep dive into how the HilbertSFC kernels are derived and why the implementation maps well to modern CPUs (FSM/LUT formulation, dependency chains, ILP/MLP, unrolling, constant folding, vectorization, gathers), see the performance deep dive notebook.
HilbertSFC achieves very high throughput on modern GPUs, reaching up to ~143 billion points per second for 3D encode of 32-bit coordinates (nbits=21) on an NVIDIA Blackwell B200. At size=64Mi, compared to an eager PyTorch implementation of the Skilling algorithm, it is roughly 3100× faster for 3D encode and 2300× faster for 3D decode.
| Implementation | Mode | 2D enc | 2D dec | 3D enc | 3D dec |
|---|---|---|---|---|---|
| HilbertSFC | triton | 225234 | 238367 | 143405 | 147926 |
| HilbertSFC | eager | 5668 | 5324 | 2745 | 2886 |
| Skilling (Pointcept) | eager | 37.9 | 48.4 | 46.4 | 63.1 |
System info: NVIDIA Blackwell B200, Ubuntu 24.04.4, Python 3.12.3, PyTorch 2.11.0, CUDA 13.0, Triton 3.6.0
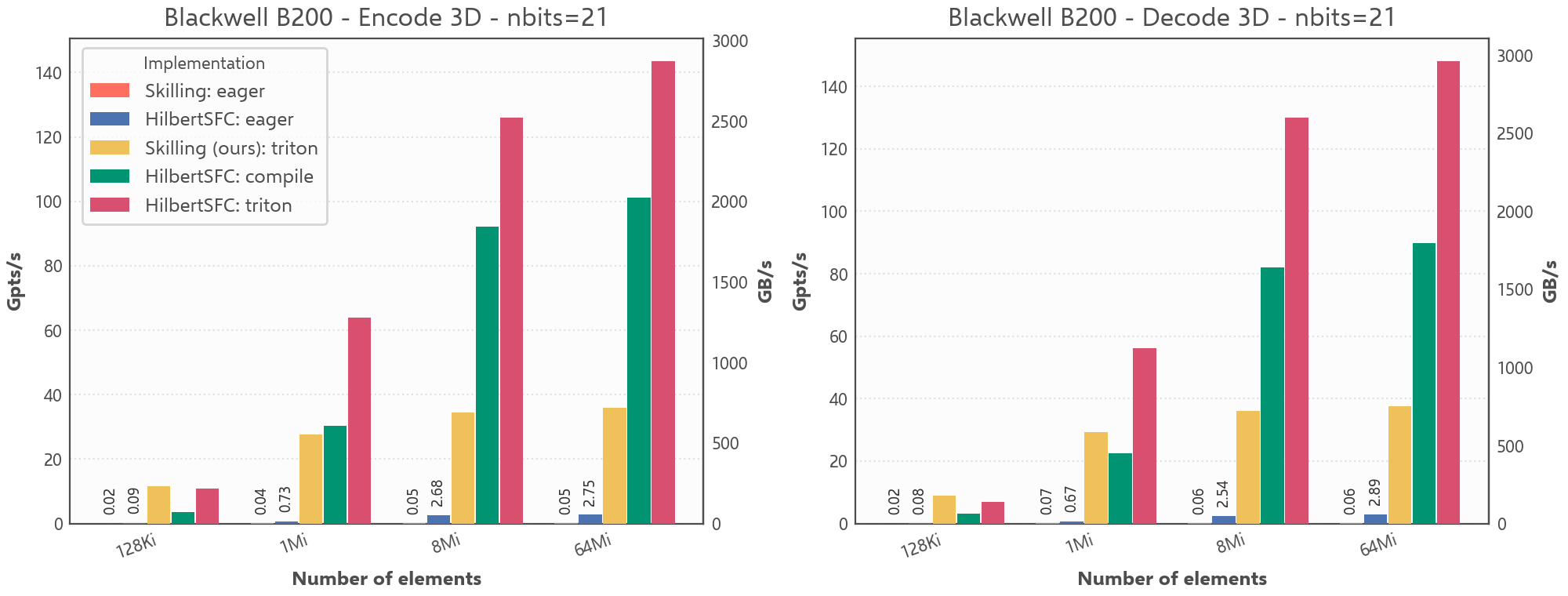
Throughput comparison for 3D Hilbert encode/decode on B200 (`nbits=21`).
See benchmark-gpu.md for more details and additional GPU benchmarks.
Install the base package with either pip or uv:
pip install hilbertsfcuv add hilbertsfcTo enable the optional PyTorch extension, install with the torch extra:
pip install hilbertsfc[torch]Note
By default, installing hilbertsfc[torch] pulls in a platform-default PyTorch build:
- Windows: CPU-only
- Linux: CUDA-enabled
If you need a specific PyTorch, CUDA, or ROCm version, follow the official
PyTorch installation instructions. Then install hilbertsfc[torch] as shown above.
Space-filling curves such as Hilbert and Morton map multi-dimensional integer coordinates onto a single scalar index while preserving spatial locality. hilbertsfc provides simple encode/decode APIs for Python scalars, NumPy arrays, and PyTorch tensors.
Use hilbert_encode_2d and hilbert_decode_2d directly on Python integers:
from hilbertsfc import hilbert_decode_2d, hilbert_encode_2d
index = hilbert_encode_2d(17, 23, nbits=10)
x, y = hilbert_decode_2d(index, nbits=10)nbits controls the coordinate domain [0, 2**nbits) on each axis. It is optional, but when you know the coordinate range ahead of time, passing a tighter value can improve performance and reduce output dtypes.
The 3D API follows the same pattern via hilbert_encode_3d and hilbert_decode_3d. The Morton/z-order functions mirror these names with morton_encode_2d, morton_decode_2d, morton_encode_3d, and morton_decode_3d.
The same functions also accept NumPy integer arrays, preserving shape and supporting batch encode/decode efficiently.
import numpy as np
from hilbertsfc import hilbert_encode_2d
xs = np.array([0, 1, 2, 3], dtype=np.uint32)
ys = np.array([3, 2, 1, 0], dtype=np.uint32)
indices = hilbert_encode_2d(xs, ys, nbits=2)This is the preferred use for high-throughput workloads on CPU. It can be further accelerated with parallel=True.
The hilbertsfc.torch frontend works with PyTorch tensors on CPU and accelerator devices. On CUDA/ROCm, contiguous tensors take the Triton path when available; otherwise execution falls back to the Torch backend.
import torch
from hilbertsfc.torch import hilbert_decode_2d, hilbert_encode_2d
device = "cuda" if torch.cuda.is_available() else "cpu"
nbits = 10
xs = torch.randint(0, 2**nbits, (4096,), dtype=torch.int32, device=device)
ys = torch.randint(0, 2**nbits, (4096,), dtype=torch.int32, device=device)
indices = hilbert_encode_2d(xs, ys, nbits=nbits)
xs2, ys2 = hilbert_decode_2d(indices, nbits=nbits)HilbertSFC also supports torch.compile. Before entering a compiled region, call precache_compile_luts(...) so LUT materialization happens outside the compiled graph.
For more details and advanced usage, see: