- [Apr 6, 2026]: 🔔 Our paper has been accepted to the ACL 2026 (Findings)!
- [Jan 26, 2026]: 🚀 We released our trained 🤗search agent and 🤗wikipedia corpus.
- [Jan 15, 2026]: 🚀 We released our full codebase and our retriever model 🤗Agentic-R_e5.
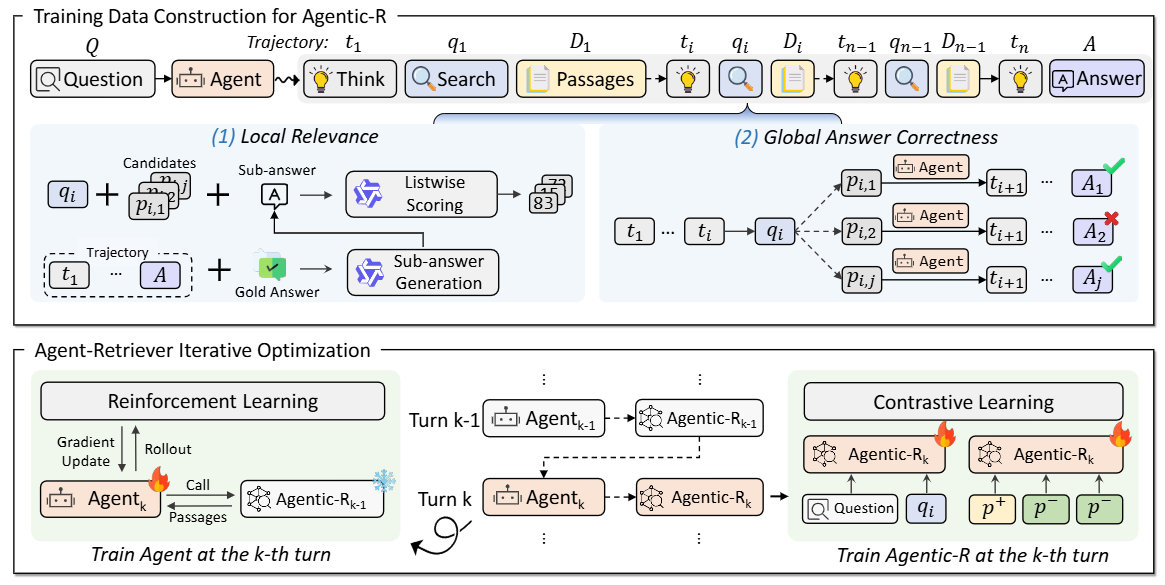
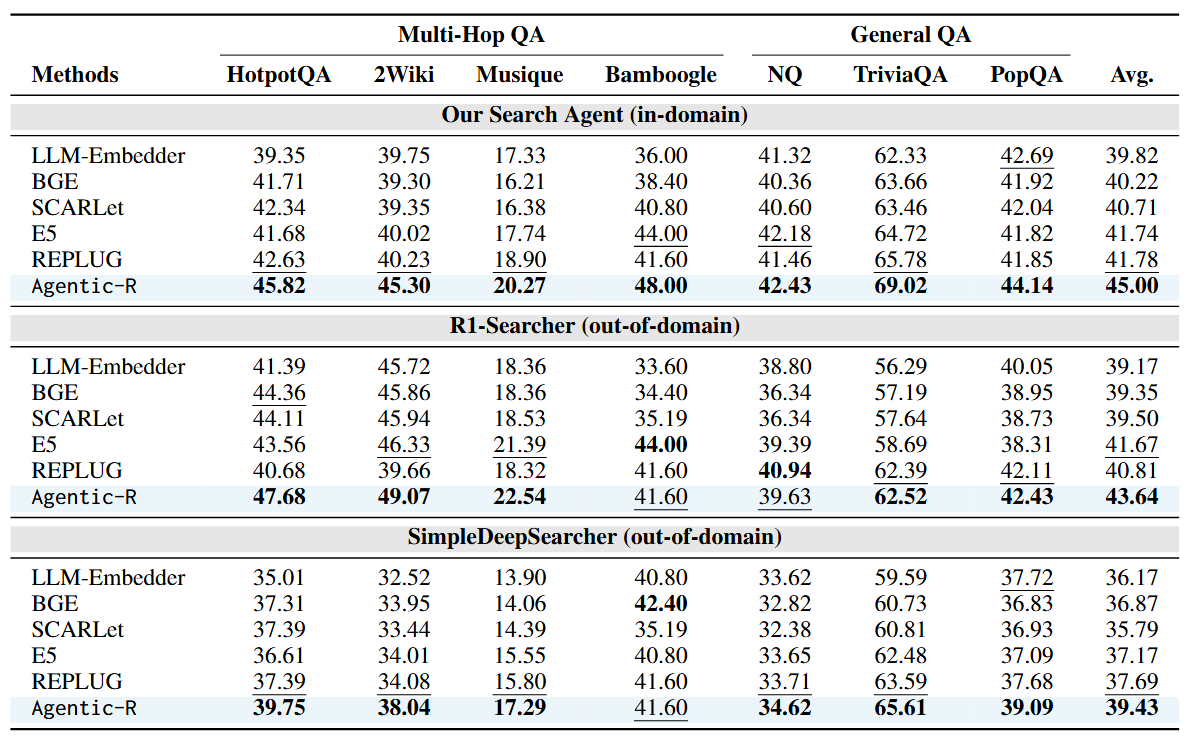
Agentic-R is a dense retriever tailored for agentic search. To train it, we first design a novel approach to measure the passage utility in agentic search and then propose an Agent-Retriever iterative optimization approach.
In this step, we will describe the required packages for inferencing with Agentic-R. We strongly recommend using a separate conda environment.
# ---------------------------------- create env ----------------------------------
conda create -n agentic-r python=3.10 -y
source ~/.bashrc
conda activate agentic-r
# ---------------------------------- install packages ----------------------------------
cd FlashRAG
pip install -e .
pip install vllm==0.10.1
pip install sentence-transformers
pip install pyserini
pip install GPUtil
pip install nvitop
pip install termcolor
pip install numpy==1.26
pip install deepspeed==0.18.0
pip install qwen_omni_utils
pip install modelscope
pip install faiss_gpu==1.7.3
pip install transformers==4.57.1a. After installing the necessary packages, remember to update the WORKSPACE_DIR and PROJECT_DIR (both should be absolute paths) in config.py. These two parameters will be used both in our inference codes and training codes. Here is a recommended directory structure:
{WORKSPACE_DIR}
├── trained_models
│ ├── Agentic-R_e5
│ └── triviaqa_hotpotqa_train-search-r1-ppo-qwen2.5-7b-em-iter1
│
├── data
│ └── FlashRAG_Dataset
│ ├── nq
│ ├── hotpotqa
│ ├── retrieval_corpus
│ └── ...
│
└── {PROJECT_DIR} (i.e., Agentic-R)
├── FlashRAG
├── Search-R1
├── tevatron
└── config.pyb. Download the datasets for testing (such as nq, hotpotqa, ...) from FlashRAG_Dataset and put them under directory {WORKSPACE_DIR}/data/FlashRAG_Dataset/. Download our trained search agent and put it under directory {WORKSPACE_DIR}/trained_models/. Download the retrieval corpus and put it under directory {WORKSPACE_DIR}/data/FlashRAG_Dataset/.
c. Download Agentic-R and put it under directory {WORKSPACE_DIR}/trained_models/ and build the wikipedia index based on the following code:
conda activate agentic-r
model_name=Agentic-R_e5
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m flashrag.retriever.index_builder \
--retrieval_method ${model_name} \
--model_path {WORKSPACE_DIR}/trained_models/${model_name} \
--corpus_path {WORKSPACE_DIR}/data/FlashRAG_Dataset/retrieval_corpus/wiki18_100w.jsonl \
--save_dir {WORKSPACE_DIR}/data/FlashRAG_Dataset/retrieval_corpus/ \
--use_fp16 \
--max_length 256 \
--batch_size 128 \
--faiss_type Flat \
--sentence_transformer \
--instruction "passage: "conda activate agentic-r
cd FlashRAG/examples/methods
bash run_exp.shNote: For our Agentic-R, the parameter agentic_retriever_input is set as True, which uses 'Question [SEP] query' for retrieval.
In our work, we design a Agent-Retriever iterative optimization framework that iteratively optimizes the search agent and our Agentic-R. Next, we will use the first iteration as an example to introduce the training codes of our search agent and Agentic-R.
a. Install environment
We strongly recommend using a separate conda environment for agent training (following Search-R1).
# ---------------------------------- create env ----------------------------------
conda create -n searchr1 python=3.10 -y
source ~/.bashrc
conda activate searchr1
# ---------------------------------- install packages ----------------------------------
pip install torch==2.4.0+cu118
pip3 install vllm==0.6.3
cd Search-R1
pip install -e .
pip install wandb
pip install flash_attn==2.7.3
pip install triton==3.0.0
pip install xformers==0.0.27.post2+cu118We recommend using another separate conda environment for retriever training.
# ---------------------------------- create env ----------------------------------
conda create -n tevatron python=3.10 -y
conda activate tevatron
cd tevatron
pip install -e .
# ---------------------------------- install packages ----------------------------------
pip install deepspeed==0.18.0
pip install accelerate
pip install transformers==4.57.1
pip install qwen_omni_utils
pip install peft
pip install torch==2.7.0
pip install faiss_gpu==1.7.3
pip install numpy==1.26.0
pip install uvicorn fastapib. Download the wiki corpus wiki18_100w.jsonl from retrieval_corpus and put these files in {WORKSPACE_DIR}/data/FlashRAG_Dataset/retrieval_corpus/.
c. Use e5-base-v2 to build the wikipedia index based on the following script:
conda activate tevatron
model_name=e5-base-v2
model_path={WORKSPACE_DIR}/llm/$model_name
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m flashrag.retriever.index_builder \
--retrieval_method ${model_name} \
--model_path $model_path \
--corpus_path {WORKSPACE_DIR}/data/FlashRAG_Dataset/retrieval_corpus/wiki18_100w.jsonl \
--save_dir {WORKSPACE_DIR}/data/FlashRAG_Dataset/retrieval_corpus/ \
--use_fp16 \
--max_length 256 \
--batch_size 256 \
--faiss_type Flat \
--sentence_transformer \Before training the search agent, run the following code to launch a retriever (we use E5 in the first iteration):
conda activate tevatron
cd Search-R1
bash retrieval_launch.shBy default, we use hotpotqa and triviaqa as our training data. The training and testing datasets are generated by scripts qa_search_train_merge.py and qa_search_test_merge.py under directory Search-R1/scripts/data_process. You could also download our pre-processed data (training.parquet and test.parquet) from here and put them under directory Search-R1/scripts/data_process/data/.
conda activate searchr1
bash train_ppo.shNote: This scirpt also includes codes for training agent based on our Agentic-R, which sends 'Question [SEP] query' to the retriever as the query. In this code, the parameter retriever.agentic_retriever_input is set as true.
a. Generate trajectory of the search agent
conda activate agentic-R
cd FlashRAG/examples/methods
bash step1_generate_trajectory.shb. Generate candidate passages
In this part, for each query generated by the search agent, we use dense retriever to retrieve training passages (for the first iteration, the retriever is E5, for the second-iteration, the retriever is trained Agentic-R after the first iteration).
conda activate agentic-R
bash step2_generate_passage_candidates.shc-1. generate local relevance (passage utility 1)
conda activate agentic-R
# first generate the sub-answer using Qwen-72B-Instruct
bash step3-0_generate_subanswer.sh
# then score the candidate passages
bash step3-1_generate_local_utility.shc-2. generate final answer correctness (passage utility 2)
conda activate agentic-R
bash step3-2_generate_global_utility.shd. construct retriever training data
python step4_construct_retriever_data.pyWe also provide the final training data for the first iteration training, you could download it from here and put it under directory FlashRAG/examples/methods/training_data/ .
cd tevatron/scripts/
bash train_agentic-R.sh
# the parameter agentic_retriever_input is set as True, which controls the query input of the retriever.After training, use the following code to build the index:
cd FlashRAG/scripts/
bash build_index_after_train.shIf you find this work helpful, please cite our papers:
@article{liu2026agentic,
title={Agentic-R: Learning to Retrieve for Agentic Search},
author={Liu, Wenhan and Ma, Xinyu and Zhu, Yutao and Li, Yuchen and Shi, Daiting and Yin, Dawei and Dou, Zhicheng},
journal={arXiv preprint arXiv:2601.11888},
year={2026}
}Our codes are build upon FlashRAG, Search-R1 and tevatron. Our work is based on the Qwen2.5 model series, and we sincerely thank the Qwen team for their outstanding contributions to the open-source community.
This project is released under the MIT License.
For any questions or feedback, please reach out to us at lwh@ruc.edu.cn.