We've seen how to cut away parts of a sequence that we don't want, how to get single values and how to inspect the contents of sequence. Those things can be seen as reasoning about the containing sequence. Now we will see how we can use the data in the sequence to derive new meaningful values.
The methods we will see here resemble what is called catamorphism. In our case, it would mean that the methods consume the values in the sequence and compose them into one. However, they do not strictly meet the definition, as they don't return a single value. Rather, they return an observable that promises to emit a single value.
If you've been reading through all of the examples, you should have noticed some repetition. To do away with that and to focus on what matters, we will now introduce a custom Subscriber, which we will use in our examples.
class PrintSubscriber extends Subscriber{
private final String name;
public PrintSubscriber(String name) {
this.name = name;
}
@Override
public void onCompleted() {
System.out.println(name + ": Completed");
}
@Override
public void onError(Throwable e) {
System.out.println(name + ": Error: " + e);
}
@Override
public void onNext(Object v) {
System.out.println(name + ": " + v);
}
}This is a very basic implementation that prints every event to the console, along with a helpful tag.
Our first method is count. It serves the same purpose as length and size, found in most Java containers. This method will return an observable that waits until the sequence completes and emits the number of values encountered.
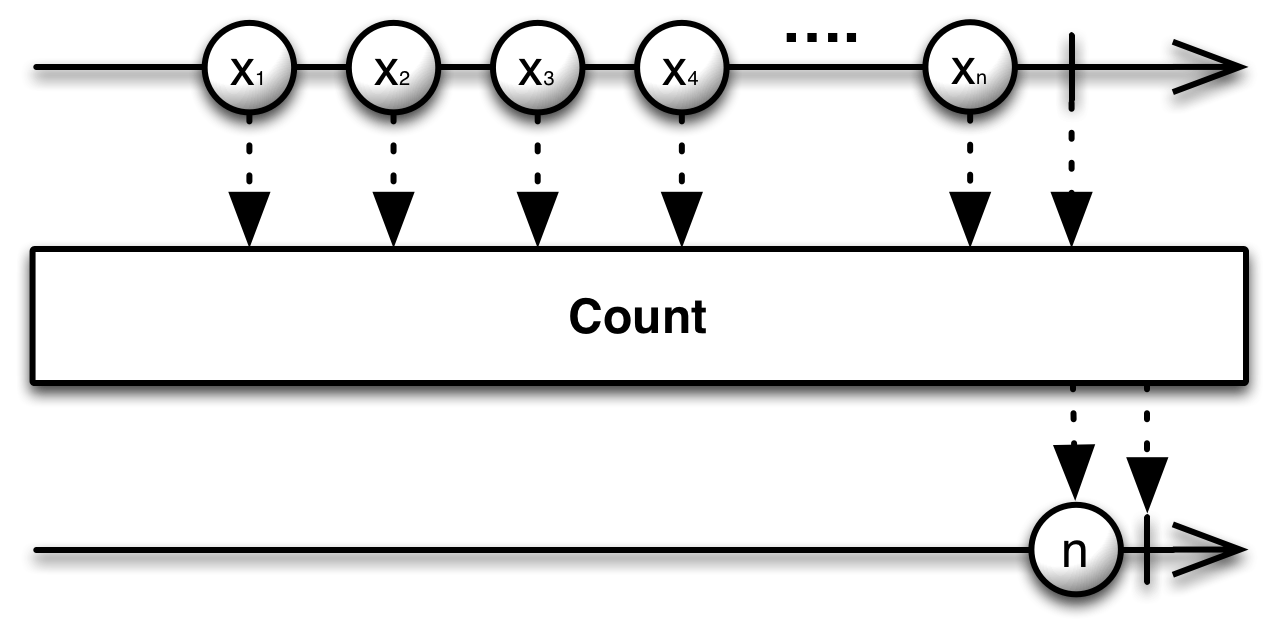
Observable<Integer> values = Observable.range(0, 3);
values
.subscribe(new PrintSubscriber("Values"));
values
.count()
.subscribe(new PrintSubscriber("Count"));Values: 0
Values: 1
Values: 2
Values: Completed
Count: 3
Count: Completed
There is also countLong for sequences that may exceed the capacity of a standard integer.
first will return an observable that emits only the first value in a sequence. It is similar to take(1), except that it will emit java.util.NoSuchElementException if none is found. If you use the overload that takes a predicate, the first value that matches the predicate is returned.
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values
.first(v -> v>5)
.subscribe(new PrintSubscriber("First"));First: 6
Instead of getting a java.util.NoSuchElementException, you can use firstOrDefault to get a default value when the sequence is empty.
last and lastOrDefault work in the same way as first, except that the item returned is the last item before the sequence completed. When using the overload with a predicate, the item returned is the last item that matched the predicate. We'll skip presenting examples, because they are trivial, but you can find them in the example code.
single emits the only value in the sequence, or the only value that met predicate when one is given. It differs from first and last in that it does not ignore multiple matches. If multiple matches are found, it will emit an error. It can be used to assert that a sequence must only contain one such value.
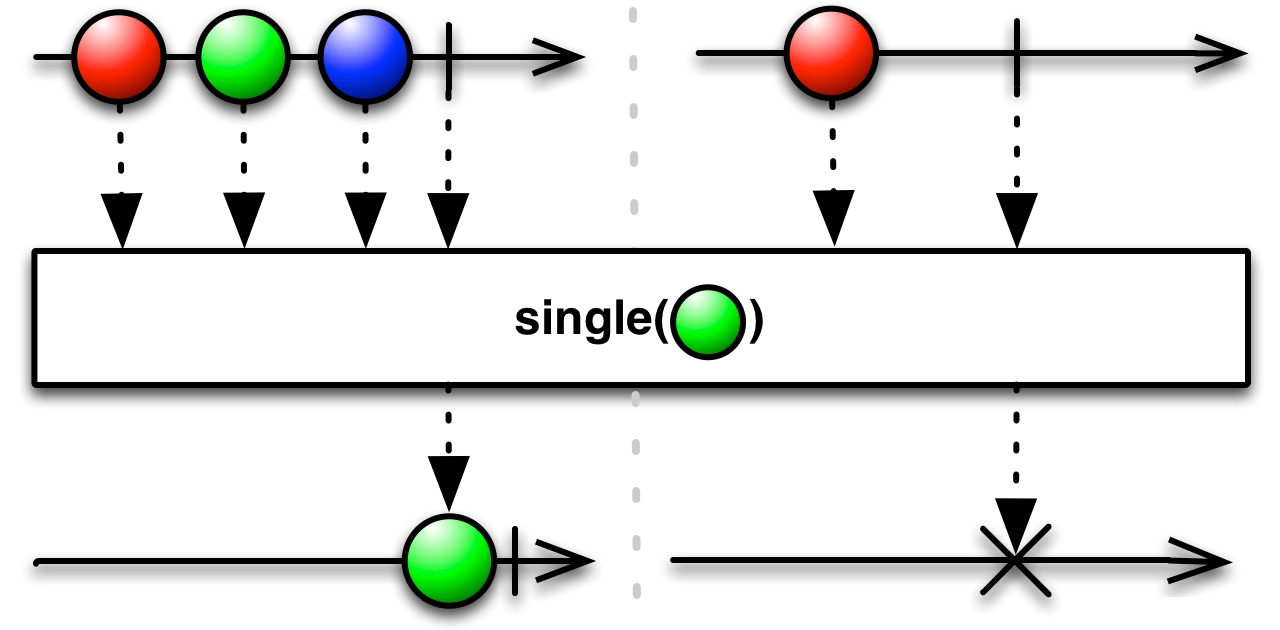
Remember that single must check the entire sequence to ensure your assertion.
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values.take(10)
.single(v -> v == 5L) // Emits a result
.subscribe(new PrintSubscriber("Single1"));
values
.single(v -> v == 5L) // Never emits
.subscribe(new PrintSubscriber("Single2"));Single1: 5
Single1: Completed
Like in the previous methods, you can have a default value with singleOrDefault
The methods we saw on this chapter so far don't seem that different from the ones in previous chapters. We will now see two very powerful methods that will greatly expand what we can do with an observable. Many of the methods we've seen so far can be implemented using those.
You may have heard of reduce from [MapReduce] (https://en.wikipedia.org/wiki/MapReduce). Alternatively, you might have met it under the names "aggregate", "accumulate" or "fold". The general idea is that you produce a single value out of many by combining them two at a time. In its most basic overload, all you need is a function that combines two values into one.
public final Observable<T> reduce(Func2<T,T,T> accumulator)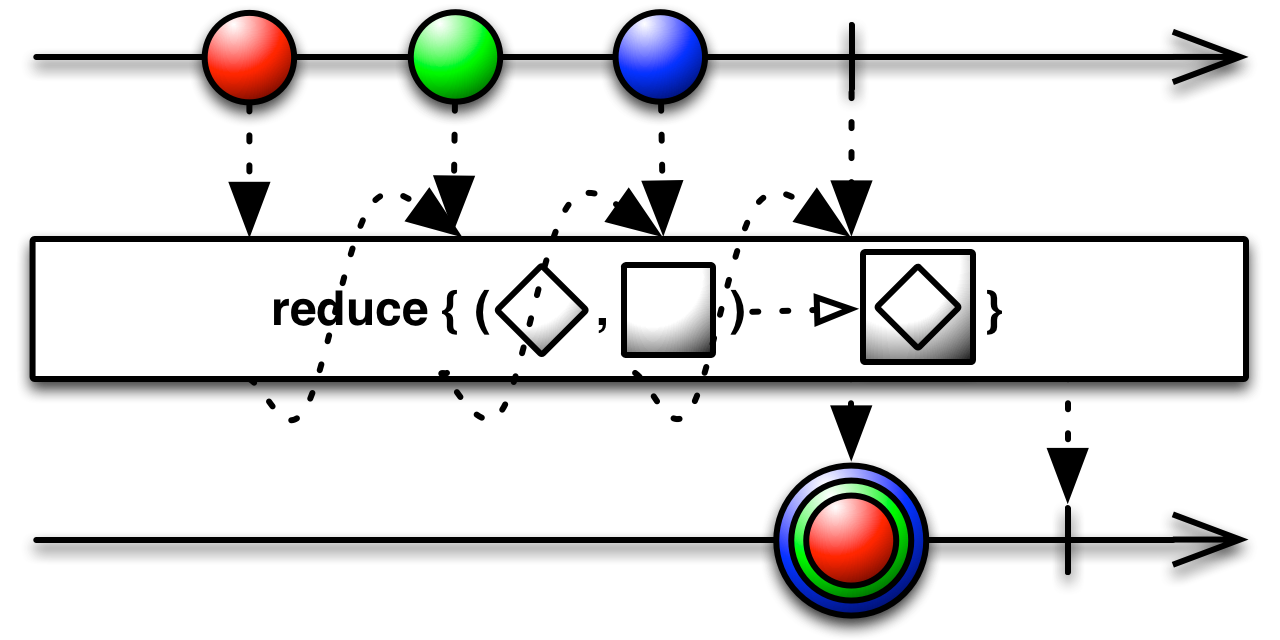
This is best explained with an example. Here we will calculate the sum of a sequence of integers: 0+1+2+3+4+.... We will also calculate the minimum value for a different example;
Observable<Integer> values = Observable.range(0,5);
values
.reduce((i1,i2) -> i1+i2)
.subscribe(new PrintSubscriber("Sum"));
values
.reduce((i1,i2) -> (i1>i2) ? i2 : i1)
.subscribe(new PrintSubscriber("Min"));Sum: 10
Sum: Completed
Min: 0
Min: Completed
reduce in Rx is not identical to "reduce" in parallel systems. In the context of parallel systems, it implies that the pairs of values can be choosen arbitrarily so that multiple machines can work independently. In Rx, the accumulator function is applied in sequence from left to right (as seen on the marble diagram). Each time, the accumulator function combines the result of the previous step with the next value. This is more obvious in another overload:
public final <R> Observable<R> reduce(R initialValue, Func2<R,? super T,R> accumulator)The accumulator returns a different type than the one in the observable. The first parameter for the accumulator is the previous partial result of the accumulation process and the second is the next value. To begin the process, an initial value is supplied. We will demonstrate the usefulness of this by reimplementing count
Observable<String> values = Observable.just("Rx", "is", "easy");
values
.reduce(0, (acc,next) -> acc + 1)
.subscribe(new PrintSubscriber("Count"));Count: 3
Count: Completed
We start with an accumulator of 0, as we have counted 0 items. Every time a new item arrives, we return a new accumulator that is increased by one. The last value corresponds to the number of elements in the source sequence.
reduce can be used to implement the functionality of most of the operators that emit a single value. It can not implement behaviour where a value is emitted before the source completes. So, you can implement last using reduce, but an implementation of all would not behave exactly like the original.
scan is very similar to reduce, with the key difference being that scan will emit all the intermediate results.
public final Observable<T> scan(Func2<T,T,T> accumulator)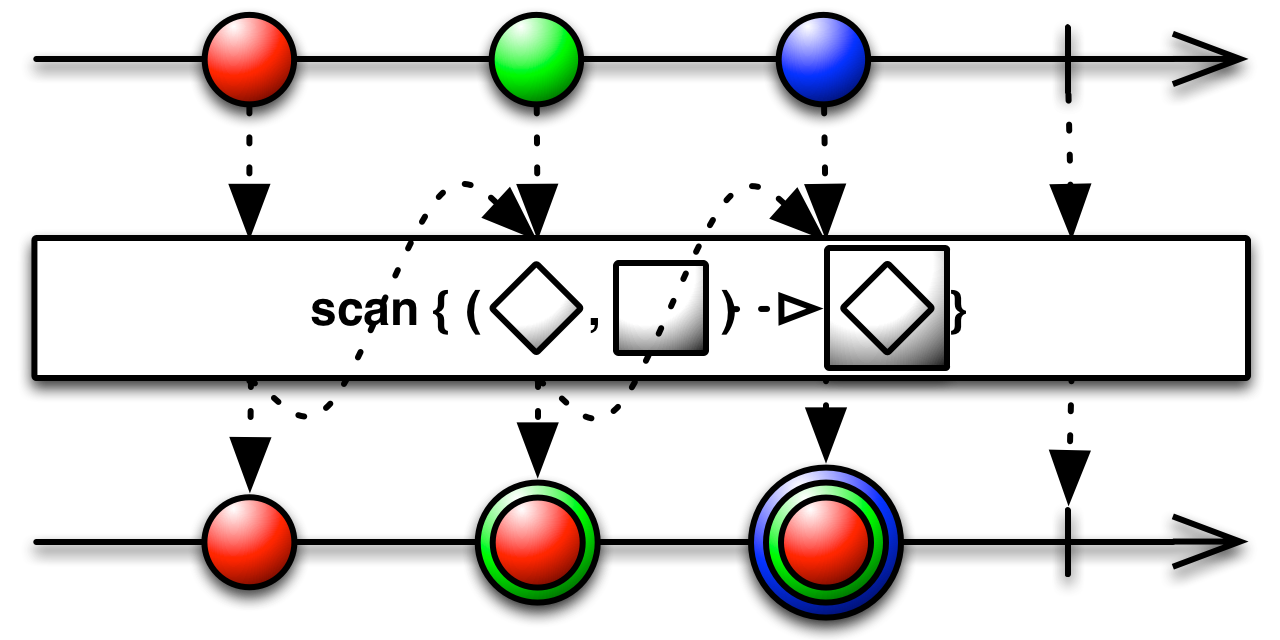
In the case of our example for a sum, using scan will produce a running sum.
Observable<Integer> values = Observable.range(0,5);
values
.scan((i1,i2) -> i1+i2)
.subscribe(new PrintSubscriber("Sum"));Sum: 0
Sum: 1
Sum: 3
Sum: 6
Sum: 10
Sum: Completed
scan is more general than reduce, since reduce can be implemented with scan: reduce(acc) = scan(acc).takeLast()
scan emits when the source emits and does not need the source to complete. We demonstrate that by implementing an observable that returns a running minimum:
Subject<Integer, Integer> values = ReplaySubject.create();
values
.subscribe(new PrintSubscriber("Values"));
values
.scan((i1,i2) -> (i1<i2) ? i1 : i2)
.distinctUntilChanged()
.subscribe(new PrintSubscriber("Min"));
values.onNext(2);
values.onNext(3);
values.onNext(1);
values.onNext(4);
values.onCompleted();Values: 2
Min: 2
Values: 3
Values: 1
Min: 1
Values: 4
Values: Completed
Min: Completed
In reduce nothing is stopping your accumulator from being a collection. You can use reduce to collect every value in Observable<T> into a List<T>.
Observable<Integer> values = Observable.range(10,5);
values
.reduce(
new ArrayList<Integer>(),
(acc, value) -> {
acc.add(value);
return acc;
})
.subscribe(v -> System.out.println(v));[10, 11, 12, 13, 14]
The code above has a problem with formality: reduce is meant to be a functional fold and such folds are not supposed to work on mutable accumulators. If we were to do this the "right" way, we would have to create a new instance of ArrayList<Integer> for every new item, like this:
// Formally correct but very inefficient
.reduce(
new ArrayList<Integer>(),
(acc, value) -> {
ArrayList<Integer> newAcc = (ArrayList<Integer>) acc.clone();
newAcc.add(value);
return newAcc;
})The performance of creating a new collection for every new item is unacceptable. For that reason, Rx offers the collect operator, which does the same thing as reduce, only using a mutable accumulator this time. By using collect you document that you are not following the convention of immutability and you also simplify your code a little:
Observable<Integer> values = Observable.range(10,5);
values
.collect(
() -> new ArrayList<Integer>(),
(acc, value) -> acc.add(value))
.subscribe(v -> System.out.println(v));[10, 11, 12, 13, 14]
Usually, you won't have to collect values manually. RxJava offers a variety of operators for collecting your sequence into a container. Those aggregators return an observable that will emit the corresponding collection when it is ready, just like what we did here. We will see such aggregators next.
The example above could be implemented as
Observable<Integer> values = Observable.range(10,5);
values
.toList()
.subscribe(v -> System.out.println(v));The toSortedList aggregator works like toList, except that the resulting list is sorted. Here are the signatures:
public final Observable<java.util.List<T>> toSortedList()
public final Observable<java.util.List<T>> toSortedList(
Func2<? super T,? super T,java.lang.Integer> sortFunction)As we can see, we can either use the default comparison for the objects, or supply our own sorting function. The sorting function follows the semantics of Comparator's compare method.
In this example, we sort integers in reverse order with a custom sort function
Observable<Integer> values = Observable.range(10,5);
values
.toSortedList((i1,i2) -> i2 - i1)
.subscribe(v -> System.out.println(v));[14, 13, 12, 11, 10]
toMap turns our sequence of T into a Map<TKey,T>. There are 3 overloads
public final <K> Observable<java.util.Map<K,T>> toMap(
Func1<? super T,? extends K> keySelector)
public final <K,V> Observable<java.util.Map<K,V>> toMap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector)
public final <K,V> Observable<java.util.Map<K,V>> toMap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector,
Func0<? extends java.util.Map<K,V>> mapFactory)keySelector is a function that produces a key from a value. valueSelector produces from the emitted value the actual value that will be stored in the map. mapFactory creates the collection that will hold the items.
Lets start with an example of the simplest overload. We want to map people to their age. First, we need a data structure to work on:
class Person {
public final String name;
public final Integer age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}Observable<Person> values = Observable.just(
new Person("Will", 25),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMap(person -> person.name)
.subscribe(new PrintSubscriber("toMap"));toMap: {Saul=Person@7cd84586, Nick=Person@30dae81, Will=Person@1b2c6ec2}
toMap: Completed
Now we will only use the age as a value
Observable<Person> values = Observable.just(
new Person("Will", 25),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMap(
person -> person.name,
person -> person.age)
.subscribe(new PrintSubscriber("toMap"));toMap: {Saul=35, Nick=40, Will=25}
toMap: Completed
If we want to be explicit about the container that will be used or initialise it, we can supply our own container:
values
.toMap(
person -> person.name,
person -> person.age,
() -> new HashMap())
.subscribe(new PrintSubscriber("toMap"));The container is provided as a factory function because a new container needs to be created for every new subscription.
When mapping, it is very common that many values share the same key. The datastructure that maps one key to multiple values is called a multimap and it is a map from keys to collections. This process can also be called "grouping".
public final <K> Observable<java.util.Map<K,java.util.Collection<T>>> toMultimap(
Func1<? super T,? extends K> keySelector)
public final <K,V> Observable<java.util.Map<K,java.util.Collection<V>>> toMultimap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector)
public final <K,V> Observable<java.util.Map<K,java.util.Collection<V>>> toMultimap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector,
Func0<? extends java.util.Map<K,java.util.Collection<V>>> mapFactory)
public final <K,V> Observable<java.util.Map<K,java.util.Collection<V>>> toMultimap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector,
Func0<? extends java.util.Map<K,java.util.Collection<V>>> mapFactory,
Func1<? super K,? extends java.util.Collection<V>> collectionFactory)And here is an example where we group by age.
Observable<Person> values = Observable.just(
new Person("Will", 35),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMultimap(
person -> person.age,
person -> person.name)
.subscribe(new PrintSubscriber("toMap"));toMap: {35=[Will, Saul], 40=[Nick]}
toMap: Completed
The first three overloads are familiar from toMap. The fourth allows us to provide not only the Map but also the Collection that the values will be stored in. The key is provided as a parameter, in case we want to customise the corresponding collection based on the key. In this example we'll just ignore it.
Observable<Person> values = Observable.just(
new Person("Will", 35),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMultimap(
person -> person.age,
person -> person.name,
() -> new HashMap(),
(key) -> new ArrayList())
.subscribe(new PrintSubscriber("toMap"));The operators just presented have actually limited use. It is tempting for a beginner to collect the data in a collection and process them in the traditional way. That should be avoided not just for didactic purposes, but because this practice defeats the advantages of using Rx in the first place.
The last general function that we will see for now is groupBy. It is the Rx way of doing toMultimap. For each value, it calculates a key and groups the values into separate observables based on that key.
public final <K> Observable<GroupedObservable<K,T>> groupBy(Func1<? super T,? extends K> keySelector)
The return value is an observable of GroupedObservable. Every time a new key is met, a new inner GroupedObservable will be emitted. That type is nothing more than a standard observable with a getKey() accessor, for getting the group's key. As values come from the source observable, they will be emitted by the observable with the corresponding key.
The nested observables may complicate the signature, but they offer the advantage of allowing the groups to start emitting their items before the source observable has completed.
In the next example, we will take a set of words and, for each starting letter, we will print the last word that occured.
Observable<String> values = Observable.just(
"first",
"second",
"third",
"forth",
"fifth",
"sixth"
);
values.groupBy(word -> word.charAt(0))
.subscribe(
group -> group.last()
.subscribe(v -> System.out.println(group.getKey() + ": " + v))
);The above example works, but it is a bad idea to have nested subscribes. You can do the same with
Observable<String> values = Observable.just(
"first",
"second",
"third",
"forth",
"fifth",
"sixth"
);
values.groupBy(word -> word.charAt(0))
.flatMap(group ->
group.last().map(v -> group.getKey() + ": " + v)
)
.subscribe(v -> System.out.println(v));s: sixth
t: third
f: fifth
map and flatMap are unknown for now. We will introduce them properly in the next chapter.
Nested observables may be confusing at first, but they are a powerful construct that has many uses. We borrow some nice examples, as outlined in www.introtorx.com
- Partitions of Data
- You may partition data from a single source so that it can easily be filtered and shared to many sources. Partitioning data may also be useful for aggregates as we have seen. This is commonly done with the
groupByoperator.
- You may partition data from a single source so that it can easily be filtered and shared to many sources. Partitioning data may also be useful for aggregates as we have seen. This is commonly done with the
- Online Game servers
- Consider a sequence of servers. New values represent a server coming online. The value itself is a sequence of latency values allowing the consumer to see real time information of quantity and quality of servers available. If a server went down then the inner sequence can signal that by completing.
- Financial data streams
- New markets or instruments may open and close during the day. These would then stream price information and could complete when the market closes.
- Chat Room
- Users can join a chat (outer sequence), leave messages (inner sequence) and leave a chat (completing the inner sequence).
- File watcher
- As files are added to a directory they could be watched for modifications (outer sequence). The inner sequence could represent changes to the file, and completing an inner sequence could represent deleting the file.
When dealing with nested observables, the nest operator becomes useful. It allows you to turn a non-nested observable into a nested one. nest takes a source observable and returns an observable that will emit the source observable and then terminate.
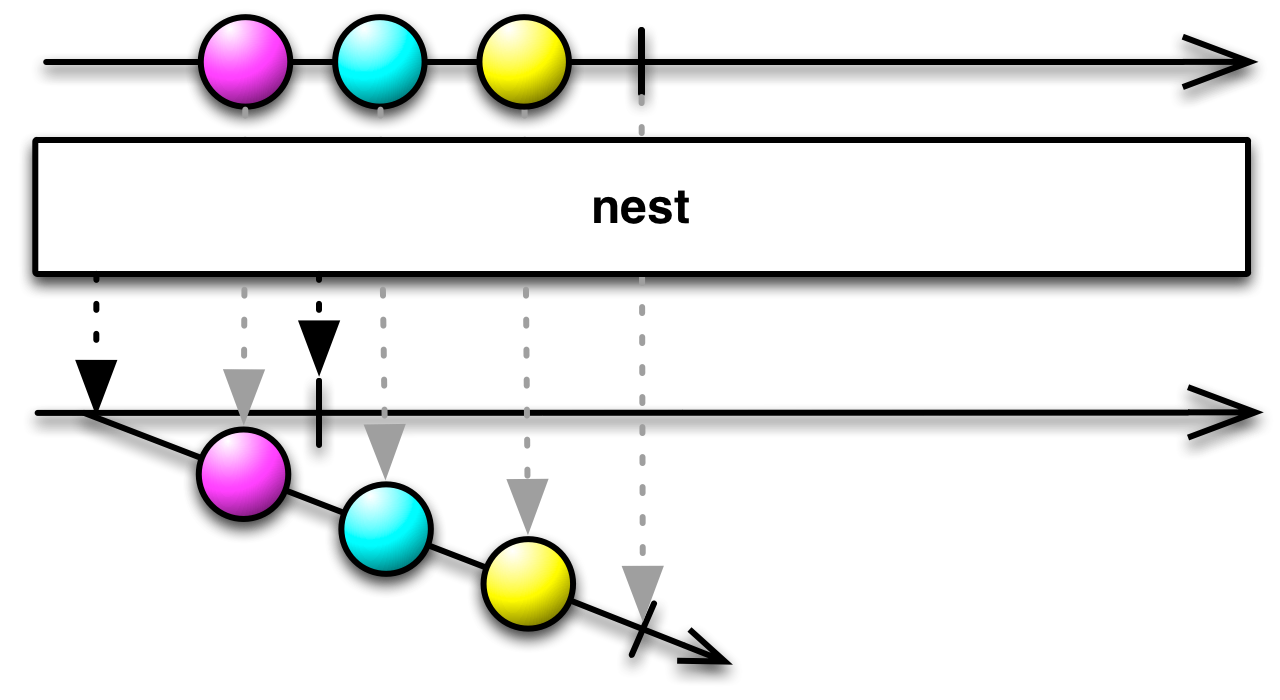
Observable.range(0, 3)
.nest()
.subscribe(ob -> ob.subscribe(System.out::println));0
1
2
Nesting observables to consume them doesn't make much sense. Towards the end of the pipeline, you'd rather flatten and simplify your observables, rather than nest them. Nesting is useful when you need to make a non-nested observable be of the same type as a nested observable that you have from elsewhere. Once they are of the same type, you can combine them, as we will see in the chapter about combining sequences.
| Previous | Next |
|---|---|
| Inspection | Transformation of sequences |